Project
EF1-20
Uncertainty Quantification and Design of Experiment for
Data-Driven Control
Project Heads
Claudia Schillings
Project Members
Matei Hanu
Project Duration
01.03.2022 − 14.09.2025
Located at
FU Berlin
Description
Methods quantifying and minimizing uncertainties in decision support systems in medicine are indispensable tools to ensure reliability of the clinical decisions. This project will focus on the simultaneous quantification of uncertainty and control of the
underlying process as well as on the minimization of uncertainties through optimal experimental design.
External Website
Related Publications
Matei Hanu, Jonas Latz, and Claudia Schillings. Subsampling in ensemble
Kalman inversion, 2023, Inverse Problems 39 094002, 10.1088/1361-6420/ace64b
Matei Hanu and Simon Weissmann. On the ensemble Kalman inversion under inequality constraints, 2024, Inverse Problems 40 095009, 10.1088/1361-6420/ad6a33
Matei Hanu, Jürgen Hesser, Guido Kanschat, Javier Moviglia, Claudia Schillings and Jan Stallkamp. Ensemble Kalman Inversion for Image Guided Guide Wire Navigation in Vascular Systems, 2024, J.Math.Industry 14, 21, 10.1186/s13362-024-00159-4
Robert Gruhlke, Matei Hanu, Claudia Schillings and Philipp Wacker. Gradient-Free Sequential Bayesian Experimental Design via Particle Methods, 2025, preprint,
https://arxiv.org/abs/2504.13320
Projects
Subsampling in ensemble Kalman inversion
We consider the Ensemble Kalman Inversion which has been recently introduced as an efficient, gradient-free optimisation method to estimate unknown parameters in an inverse setting. In the case of large data sets, the Ensemble Kalman Inversion becomes computationally infeasible as the data misfit needs to be evaluated for each particle in each iteration. Here, randomised algorithms like stochastic gradient descent have been demonstrated to successfully overcome this issue by using only a random subset of the data in each iteration, so-called subsampling techniques. Based on a recent analysis of a continuous-time representation of stochastic gradient methods, we propose, analyse, and apply subsampling-techniques within Ensemble Kalman Inversion. Indeed, we propose two different subsampling techniques: either every particle observes the same data subset (single subsampling) or every particle observes a different data subset (batch subsampling).

Our first method is single-subsampling, where each particle obtains the same new data set when data is changed.

The second method is batch-subsampling, where each particle can obtain different data sets at each data change.

In case of a linear forward operator both methods converge to the same solution as the EKI. The red line represents the EKI, blue is single-subsampling and green is batch-subsampling. In the left image we illustrate the error to the true solution in the parameter space. The right image illustrates the error in the observation space.

Finally, we also considered single-subsampling for a non-linear forward operator. We can see that our method (right image) computes the same solution as MATLABs fmincon optimizer (left image) as well as the EKI (middle image).
Note that our method computes the same results as the EKI, but at lower computational cost. Hence, this method is a suitable alternative in case of high-dimensional data.
Ensemble Kalman Inversion for Image Guided Guide Wire Navigation in Vascular Systems
In this project we consider the challenging task of guide wire navigation in cardiovascular interventions, focusing on the parameter estimation of a guide wire system using Ensem- ble Kalman Inversion (EKI) with the subsampling technique that was introduced in the latter project. High resolution images are one example of high-dimensional data and therefore the EKI might become computationally infeasible. We expand the theory introduced in the latter project to non-linear forward operators and apply it to on the parameter estimation of our guide wire system. Numerical experiments with real data from a simplified test setting demonstrate the potential of the method.

For our experiments we have images like the left one, where a vertical force is applied to one end of the rod. For the mathematical analysis we apply a distance transformation to it, i.e. after cropping everything out of the image that isn’t the wire and turning the image into a black and white image, we calculate for each pixel a relative distance to the wire (right image). By doing this we define a metric that allows us to measure how ‘close’ images are to another and are able to minimize the difference.
We shorty describe the algorithm,
- Given an initial density and energy dissipation we apply a constant force at one end of the rod while we fix the other. This results in the left image above.
- We crop everything beside the rod out of the picture, turn it into a black and white picture and apply distance transformation to it.
- We calculate the distance of the images to one another.
- We optimize for the density as well as the energy dissipation, w.r.t. to the image distances.
For the optimisation we consider the pixel values of the images, since the amount of pixels is extremly large, standard optimizers as well as the EKI might have computational problems. Due to this we consider the above introduced subsampling approach for optimization.

The left image illustrates the original rod and the images that we obtain through the optimized values of density and energy dissipation. The right hand image shows the computed rods without the original image. We can see that both computed solutions are similar to another as well as similar to the original image. The residuals converge at the same rate, they only differentiate themselves in constant. This can be seen in the image below.

On the ensemble Kalman inversion under inequality constraints
The EKI in its general form does not take constraints into account, which are essential and often stem from physical limitations or specific requirements.
Based on a log-barrier approach, we suggest in this project adapting the continuous-time formulation of EKI to incorporate convex inequality constraints. We underpin this adaptation with a theoretical analysis that provides lower and upper bounds on the ensemble collapse, as well as convergence to the constraint optimum for general nonlinear forward models. We showcase our results through two examples involving partial differential equations (PDEs).

We illustrate here the solutions obtained through our algorithm for a 2D-Darcy flow. The upper left image illustrates the ground truth, The lower left shows the solution computed by the EKI in its general form, our method, the EKI with boundary constraints, is illustrated in the bottom right and the upper right image shows the reference solution, which is computed through an optimizer. The grey planes illustrate bounds on the diffusion coefficient, we can see that our method satisfies the bounds and is identical to the optimizer solution, whereas the EKI in its general form does not lie in the bounds.
Barrier methods penalize parameter values that move to close to the bounds, they force the particles to stay within the constraints by deactivating directions pointing towards areas that do not fulfill the constraints. This penalty is applied through a parameter, that in theory has to go to infinity for the algorithm to converge to the optimal point (Karush-Kuhn-Tucker point). However, due to the increasing value of the parameter the algorithm becomes computationally slower. To solve this problem we begin the algorithm with a low penalty parameter and increase the parameter over time.

This image illustrates the errors of the parameters (left) as well as the functionals (right). We can see that the algorithm with the largest penalty parameter converges the fastest in both images, however the method with the increasing penalty parameter, reaches the same error level after some time. However, the computational time needed to achieve this result is much lower.
Gradient-Free Sequential Bayesian Experimental Design via Particle Methods
As mentioned above, the Bayesian framework for UQ offers a principled way to incorporate observational data and thereby reduce uncertainty. Since data acquisition is often costly or constrained, this motivates the use of Bayesian Optimal Experimental Design (BOED), which aims to maximize the expected information gain from the collected data.
In this project, we propose a gradient-free BOED framework tailored to scenarios where gradients of the forward model are unavailable or prohibitively expensive to compute. Specifically, we combine EKI as a derivative-free optimizer with Affine-invariant Langevin dynamics (ALDI) as a sampling method in a sequential design setting. To mitigate the high computational cost, we employ Gaussian approximations for efficient estimation of expected utilities. This approach yields robust, adaptive experimental designs while avoiding the need for adjoint computations or gradient information.
The framework thus enables scalable and flexible BOED in high-dimensional or computationally demanding settings, with particular emphasis on PDE-based inverse problems. The resulting methodology improves the informativeness of data used for Bayesian inference, thereby enhancing the reliability of calibrated models. It also provides a practical pathway toward applying BOED in real-world applications where computational and modeling constraints have traditionally posed significant barriers
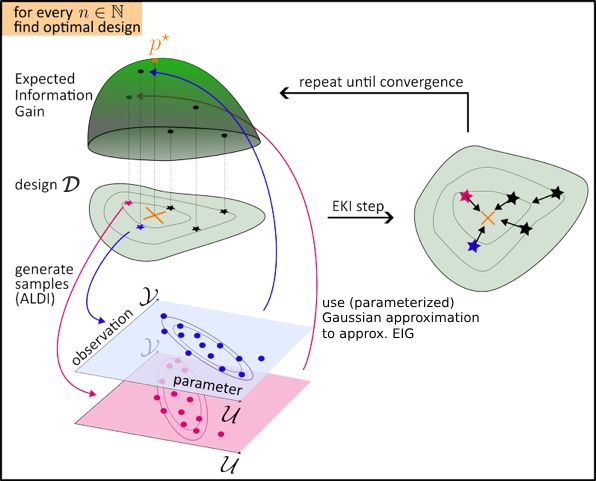
Illustration of the proposed algorithm: our method combines the EKI with the gradient-free version of ALDI as derivative-free method to compute the optimal design parameters.
In BOED, the design is determined by maximizing a utility function that averages over all possible observations. Exact evaluation of this utility is generally infeasible, as the evidence and posterior distribution often lack closed-form expressions. To address this, we employ Gaussian or Laplace approximations to efficiently approximate the utility. Depending on whether the approximation is applied to the evidence or the posterior, this leads to computable upper and lower bounds. We illustrate our computations on a PDE based model.
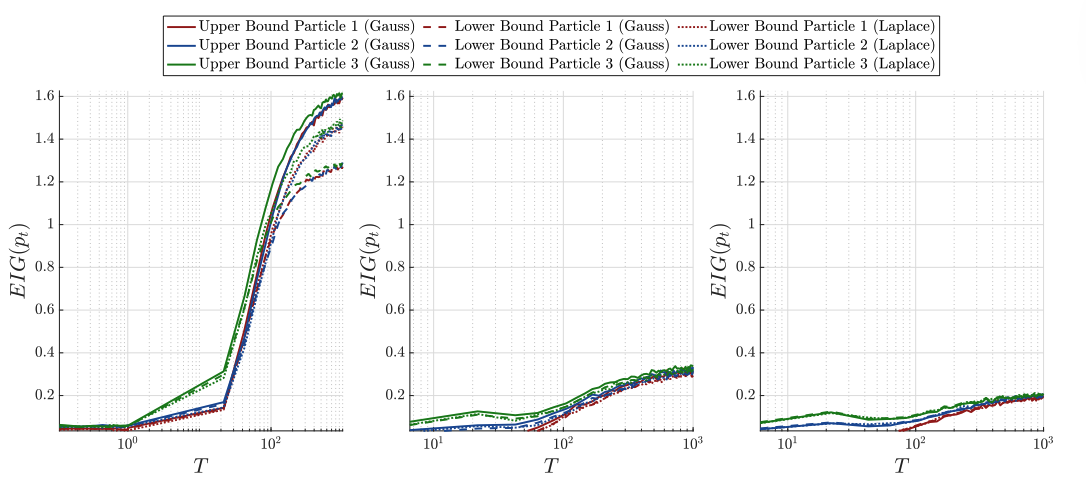
We consider a sequential experimental setup with three design steps and adopt the expected information gain (EIG) as the utility function. Our EKI method employs three particles, illustrated in the figure. The upper bound is computed using a Gaussian approximation, while the lower bound is evaluated both with a Laplace approximation and, for comparison, also with a Gaussian approximation. Across all three steps, the EKI particles converge toward the optimal design as the EIG increases over time. Moreover, the Laplace approximation consistently provides a tighter lower bound than the Gaussian approximation, however, at higher computational cost. This observation motivates a hybrid strategy: employing the Gaussian approximation in the early stages to quickly approach the optimal design, and subsequently switching to the Laplace approximation for improved accuracy. Exploring this adaptive combination is left for future work.